A lot of organisations set up security policies so that users will be locked out if they enter the wrong password too many times. The idea is to prevent brute force attacks, where an attacker could sit there all day running through the dictionary until they guess the correct password. The downside is that this can lead to Denial of Service attacks, i.e. someone could deliberately enter the wrong password in order to stop other people from logging in. A better solution is to have a throttle, e.g. if you enter the wrong password then you have to wait 30 seconds until your next attempt. That would slow down an attacker without being a major inconvenience to legitimate users. Unfortunately, Windows domain controllers don’t support this natively, and I haven’t come across any third party software that does the same thing.
Leaving aside deliberate attacks, sometimes this can happen by accident. A common cause is that someone changes their password, but their mobile device still has the old password (to access email), and it automatically makes enough attempts to lock the account. There are some other common causes linked to a recent password change, e.g. if there is a scheduled task or a service running under a user’s account, or if they have mapped drives or cached credentials for websites.
A while back, I came across a case that was a bit more interesting. The root cause turned out to be a mismatch in authentication protocols, so the error messages were misleading: there was never actually an incorrect password! Read on for the technical details.
In this particular situation, there were several users getting locked out frequently. However, it was erratic: they might get locked out several times in an hour (with the service desk unlocking their account each time), and then not at all for several hours after that. This made it difficult to replicate the problem.
Our first step was to inspect the Security log on a domain controller, searching for event ID 4740. This will tell you which account was locked out, and which client machine it occurred on. If that machine is a desktop or laptop rather than a mobile device, you can eliminate one possible cause. Unfortunately, the event won’t tell you which process or application was responsible (e.g. outlook.exe).
We tried the Netwrix Account Lockout Examiner; in theory this can identify the process if your logs are sufficiently detailed, but that didn’t work for us. We only got to the stage where we had a shortlist of about 20 possible processes. Still, it was useful to view all the currently locked out accounts in the domain, and there’s a freeware edition of the tool.
You should also be aware of the password history check feature (aka “n-2”):
“Before a Windows Server 2003 operating system increments badPwdCount, it checks the invalid password against the password history. If the password is the same as one of the last two entries that are in the password history, badPwdCount is not incremented for both NTLM and the Kerberos protocol. This change to domain controllers should reduce the number of lockouts that occur because of user error.”
In other words, using your old password won’t let you in, but it won’t lock you out either.
As a test, we took one user who was repeatedly locked out and gave them a completely new profile. That way, there couldn’t be any lingering traces of the old password, but the problem kept occurring.
We then had another look at the Security log on a domain controller. This time we filtered for event ID 4771 (“Kerberos pre-authentication failed”). Like 4740, this tells you which user was involved. It also includes a failure code: 0x12 means “account locked” and 0x18 means “bad password”. In this case, we only saw 0x12 for the affected users, not 0x18. That implies that they weren’t using Kerberos when they entered the bad password; these errors occurred after the account had already been locked out by a different protocol.
Just to recap, Windows supports 4 authentication protocols:
- LAN Manager
- NTLM
- NTLMv2
- Kerberos
The default approach is to negotiate: clients will attempt Kerberos authentication first, but if that fails then they’ll fall back to the NTLM family.
You can configure which of the older protocols you want to use, either via the LMCompatibilityLevel registry value or the Network security: LAN Manager authentication level Group Policy setting. It’s worth reading the Microsoft web page for more details, but here’s a quick summary:
| Level | Setting |
|---|---|
| 0 | Send LM & NTLM responses |
| 1 | Send LM & NTLM – use NTLMv2 session security if negotiated |
| 2 | Send NTLM response only |
| 3 | Send NTLMv2 response only |
| 4 | Send NTLMv2 response only. Refuse LM |
| 5 | Send NTLMv2 response only. Refuse LM & NTLM |
The default behaviour varies. It’s worth noting that the Group Policy editor disagrees with the Microsoft website (link above); the GP editor says that the default behaviour is “Send NTLMv2 response only” for clients and servers, whereas the website says that this only applies to servers and the setting is undefined for clients. I don’t know which of those is correct. Also, if you’ve got any XP/2003 machines around (which have been unsupported for several years!), they will have different settings to a more modern OS. So, the safest approach is to define this setting explicitly yourself, then you can make an informed choice about which protocols your devices/applications need to use.
Be particularly careful about the “Default Domain Controllers” GPO. Here’s an older version of the LAN Manager authentication level web page, which says:
“In Windows Server 2003, the Default Domain Controllers Policy was Send NTLM response only, which changed to Not defined in later versions.”
Microsoft removed that from the live version of the web page, but I can vouch for this being true based on my personal experience; I migrated an NT domain to Active Directory using Windows Server 2003 for the domain controllers. The key point here is that even if you upgrade your domain controllers to a newer version of Windows, and raise the functional level of the forest/domain, that won’t modify the existing GPO. You need to change (or undefine) this setting, otherwise you’ll be stuck with it forever.
Whichever setting you choose, you want to be consistent across the network. We found a blog post by Dave Fisher which pointed us in the right direction: I moved my PDCE role and accounts started locking out! Quoting from that post:
“In Fred’s case, it turned out that his XP clients all had a setting of 0: Send LM and NTLM responses, while his new PDC emulator had a setting of 5: Send NTLM v2 response only/Refuse LM and NTLM.”
In our case, we hadn’t replaced the domain controllers recently or moved any roles between them. However, we knew that the GPO for our domain controllers was also set to 5 (like in Fred’s example), and had been for a long time.
Looking at some client machines, we searched for this registry value:
reg query HKLM\System\CurrentControlSet\Control\Lsa /v LMCompatibilityLevel
NB LMCompatibilityLevel is a value, not a key! The following command is wrong:
reg query HKLM\System\CurrentControlSet\Control\Lsa\LMCompatibilityLevel
Tip: you can use psexec from the SysInternals suite to check remote machines, without having to log into them directly.
On a default installation of Windows 7 or Windows 10, it will say:
ERROR: The system was unable to find the specified registry key or value.
If this setting wasn’t defined, the default behaviour worked fine with our domain controllers.
However, we found a setting on the machines that caused lockouts:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Lsa
LMCompatibilityLevel REG_DWORD 0x0
I.e. those machines were configured with “Send LM & NTLM responses”. The description for this setting is: “Client devices use LM and NTLM authentication, and they never use NTLMv2 session security. Domain controllers accept LM, NTLM, and NTLMv2 authentication.”
In our case, the domain controllers GPO also enabled this setting: Network security: Do not store LAN Manager hash value on next password change. Again, this had been in place for a long time, which means that clients couldn’t be using the original LAN Manager authentication (assuming that the users had changed their password since the policy was set). So, the machines with LMCompatibilityLevel set to 0x0 would always use NTLM authentication, never NTLMv2.
NTLM and NTLMv2 both use challenge/response. The server sends an 8-byte challenge (a nonce) to the client; the client will encrypt the challenge using a hash of the password, then send the response. In this case, the clients would only send an NTLM response, but the domain controllers would refuse NTLM responses and only accept NTLMv2 responses. That means that the encrypted versions of the challenge wouldn’t match. Ideally, the server would flag this as “incompatible protocol” rather than “bad password” and wouldn’t lock the account. Sadly, that’s not the way it works in practice.
This setting only affected some client machines, which explains why not all of the end users were experiencing account lockouts. There were a few possible causes for this:
- At some point in the dim and distant past, there had been a group policy to enforce that setting, which was later removed. However, the setting stayed in the registry due to tattooing. In brief, when you define a setting it updates the registry. When you stop defining the setting, the computer doesn’t know the previous registry value, so it can’t revert to it. It will keep the new value, but this is now read/write rather than read-only. (More specifically, GPO won’t keep overwriting the registry setting every 90 minutes.)
- There was a local security policy.
- Someone had configured this registry setting manually. (That might have been unintentional, e.g. if a setup program for a particular application changed the registry.)
For options 2 and 3, it’s plausible that the change was made on one machine, then this PC was used as a master to create an image which was applied to other machines.
In our case, we discovered that it was option 2: at least one of the clients had a local security policy.
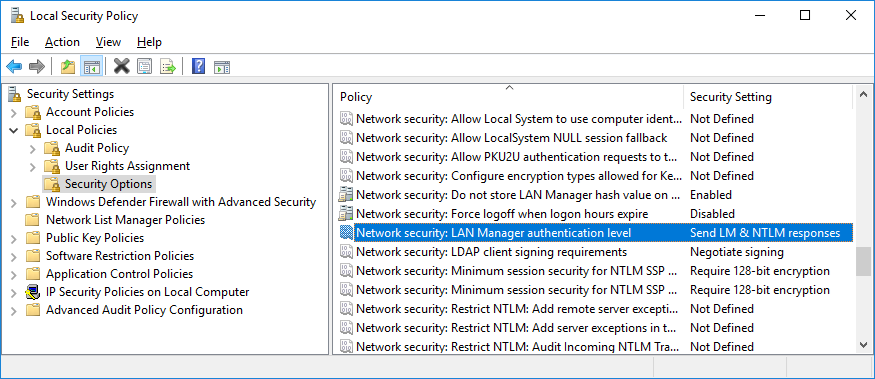
When we changed this setting to a higher level, the person using that machine no longer experienced lockout problems. As an interesting note, once this setting is defined locally, you can’t change it back to “Not defined”. (You can do that in GPO, but not in the Local Security Policy.)
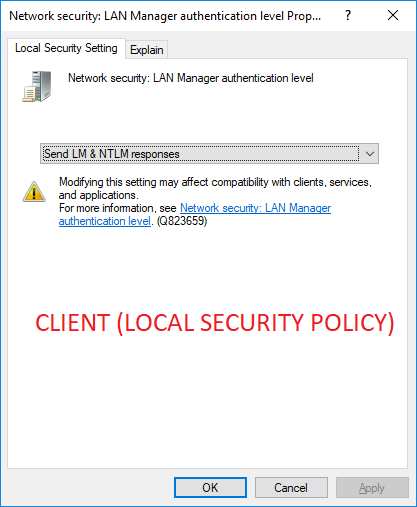
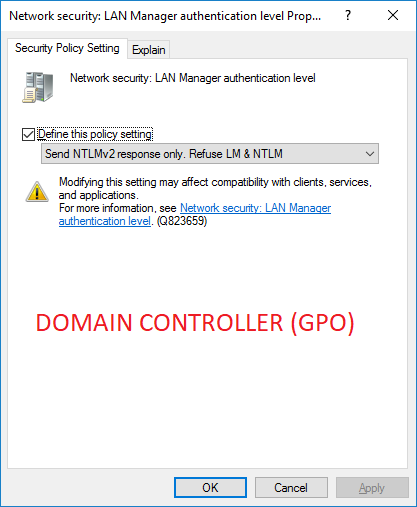
However, GPO from Active Directory will always override the local policy for a machine, so once you’ve configured this setting centrally you don’t need to worry about any conflicts.
So, if this was the underlying cause, what was the catalyst? Why did this problem suddenly start occurring, when everything had been fine for a while? As I said above, Windows will always use Kerberos authentication if possible. So, this mismatch only became relevant when Kerberos authentication failed, e.g. because a server didn’t have the correct SPN records or because the clocks drifted too far out of sync.
Ideally, you should block LM, NTLM, and NTLMv2, and only use Kerberos. However, that’s easier said than done! Ned Pyle has written a very good blog post about this: NTLM Blocking and You: Application Analysis and Auditing Methodologies in Windows 7. As he said, you could easily spend 6 months on the audit stage. Basically, you need to look at the NTLM logs and identify why that traffic isn’t using Kerberos. Once you’ve done that, move to the next item in the logs. As you proceed, you will gradually whittle down the list. I’ll cover some specific “gotchas” that I’ve come across in future blog posts.
Leave a Reply